Data Processing and Database
Data Processing and Database
Introduction to Data Processing:
Data is a collection of raw facts and figures which are unorganized, but able to organize into meaningful and useful information. Data can be manipulated to produce output.
Information is the processed data in a meaningful and useful form i.e. after processing the data we can get the information. Information on one thing may be the data of another. Hence information is the data arranged in an order and form that is useful to people who receive it.
Data processing is the conversion of data into usable and desired form. This conversion or “processing” is carried out using a predefined sequence of operations either manually or automatically. Most of the data processing is done by using computers and thus done automatically. The output or “processed” data can be obtained in different forms like image, graph, table, vector file, audio, charts or any other desired format depending on the software or method of data processing used.
Data processing is undertaken by any activity which requires a collection of data.
This data collected needs to be stored, sorted, processed, analyzed and presented.
Data Processing Operations:
To process the data certain fundamental operations must be performed. These operations are:
- Recording: Recording is the transforming data into a permanent form.
- Classifying: it involves grouping of similar item or transaction in a group.
- Sorting: it is a arranging of data or transaction in ascending or descending order.
- Calculation: In this stage chunk of raw data is calculated, manipulated, and done series of operations to get meaningful information as an output. It is adding, subtraction, multiplying, or dividing data to produce useful result.
- Summarizing: It involves the consolidating (combining) of data emphasizing main points.
- Presenting and Reporting: Presenting the data includes the pictorial representation of the processed data or output by using graphs, charts, maps and other methods. These methods help to makes it much more comfortable and quicker to understand. Various methods of data presentation can be used to present data and information such as text form, tabular form, graphical form etc.
File Processing:
Processing of data and information stored in a file is called file processing. File processing consists of creating, storing, and/or retrieving the contents of a file from a recognizable medium.
For example, it is used to save word-processed files to a hard drive, to store a presentation on floppy disk, or to open a file from a CD-ROM.
There are two types of file processing used commonly in data processing are:
- Sequential file processing
- Direct file processing
Sequential file processing:
In a sequential file, record are stored one after another in ascending or descending order determined by key field value of records. In sequential file processing to meet or locate any particular point or object computer must read or meet all the preceding points. This means sequential file processing records are accessed one after another in sequential fashion. That is, first reads and process the first record, then the second record and so on.
For example, in payroll system record of employee is organized sequentially by employee_id. In magnetic tape files are stored sequential fashion.
Advantage:
- They are simple to use and understand.
- They need relatively inexpensive I/O devices for storage and processing.
- They are easy to organized and maintain.
- No need of special technicalkk knowledge to use.
Disadvantage:
- They required extra resource of sorting the files before using them for processing.
- It leads to data redundancy problem because same data can be stored in different place by different id.
Direct or Random File Processing:
Many applications require processing of data immediately whenever it occurs. In direct file processing, desired record can be process directly located by its key field value without having to search through a sequence of other record.
For example, airline or railway reservation, when a passenger makes a reservation request, the computer which maintaining the reservation record directly access the database and update seat position for specific date. Magnetic disk uses the direct file processing principle where we can move directly in particular position by entering time.
Advantage:
- It does not require data to be stored in sequence before processing.
- Any record can be quickly store and retrieved directly by giving key address.
- They are processed whenever generated.
Disadvantage:
- They required special technical knowledge to use.
- They required relatively expensive hardware and software resources.
- Due to address generation extra resource needed.
Database:
Data is a collection of a distinct small unit of information. It can be used in a variety of forms like text, numbers, media, bytes, etc. it can be stored in pieces of paper or electronic memory, etc.
Database is an organized collection of data. More specifically, a database is an electronic system that allows data to be easily accessed, manipulated and updated.
You can organize data into tables, rows, columns, and index to make it easier to find relevant information.
Database handlers create a database in such a way that only one set of software program provides access of data to all the users. The main purpose of the database is to operate a large amount of information by storing, retrieving, and managing data.
There are many dynamic websites on the World Wide Web nowadays which are handled through databases. For example: a website that checks the availability of rooms in a hotel. It is an example of a dynamic website that uses a database.
There are many databases available like MySQL, Sybase, Oracle, MongoDB, Informix, SQL Server, etc. Modern databases are managed by the database management system (DBMS).
A cylindrical structure is used to display the image of a database.

Entity Relationship (E-R) Diagram:
It is the real world model which represents the entities constraints in the database. The entities are further described in the database using attributes. The relation between entities is shown using the relationship. E-R model is represents diagrammatical using an E-R diagram.
Entity: An entity is the basic unit for modeling. It is a real world objects that exists physically which are tangible like students, employees, machines etc. or conceptually which are intangible like an event, job title etc.
For example, a student information system may consist of entities like student_profile, marks, course etc.
Attributes: An attribute describes some properties or characteristics of the entity. For example, student_profile may consist of attributes like student_name, student_address, student_age etc.
Relationship: An association or link between two entities is represented using a relationship. For example, student enroll in course is a relationship set between entities students and course.
There are four kinds of relationships.
One-to-One: An entity of A is linked with at most one entity of B and vice versa.
One-to-Many: An entity of A is liked with many entities of B, but an entity of B is liked with at most one entity of A.
Many-to-One: Many entities of A are liked with at most one entity of B, but an entity of B is liked with many numbers of entities of A.
Many-to-Many: An entity of A is linked with many numbers of entities of B and vice versa.
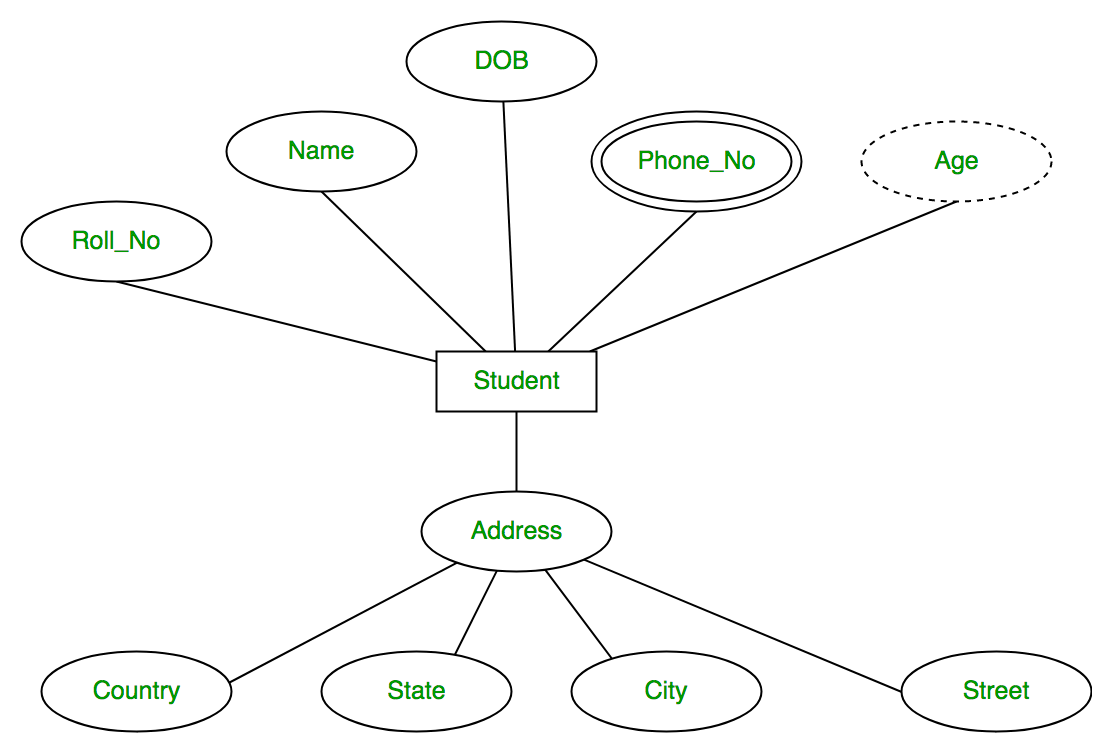
Fig: Entity Relationship Diagram.
Here, Phone_No is multivalued entity which means one student can have multiple phone numbers. Age is the derived attribute which derived from DOB attribute.
Relational Database:
Data is organized as logically independent tables. Relationships among tables are shown through shared data. The data in one table may reference similar data in other tables, which maintains the integrity (completeness) of the links among them. This feature is referred to as referential integrity – an important concept in a relational database system. Operations such as "select" and "join" can be performed on these tables. This is the most widely used system of database organization.
An entity set usually has some attributes whose values are distinct for each individual entity is called key. Two entities don’t allow having exactly same value for all attributes.
Primary Key:
A primary key is a special key which uniquely identifies each record in a table. It is very important in the relational database to have a unique identifier in each row of a table and primary key is just the thing you need to uniquely identify a tuple within a table. A tuple represents a set of value attributes in a relational database.
A primary key may refer to a column or a set of columns in a relational database table used to implicitly identify all records in the table. The primary key must be unique for each record as it acts as a unique identifier and it should not contain Null values. Each database must have one and only one primary key.
Foreign Key:
A foreign key refers to a field or a collection of fields in a database record that uniquely identifies a key field of another database record in some other table. In simple terms, it establishes a link between records in two different tables in a database.
It can be a column in a table that points to the primary key columns meaning a foreign key defined in a table refers to the primary key of some other table. References are crucial in relational databases to establish links between records which is essential for sorting databases. Foreign keys play an important role in relational database normalization especially when tables need to access other tables.
In the figure below Codigo is the primary key of the table & Depart is the foreign key of table.

Fig: Primary Key and Foreign Key
Data Mining:
Introduction to Data Mining:
Data mining is the process of analyzing hidden patterns of data according to different perspectives for categorization into useful information, which is collected and assembled in common areas, such as data warehouses, for efficient analysis, data mining algorithms, facilitating business decision making and other information requirements to ultimately cut costs and increase revenue. Data mining is also known as data discovery and knowledge discovery.
Following figure illustrates the necessary stages in data mining.
Fig: Stages in Data Mining
- Selection: in the initial stage target data is selecting and segmenting according to some criteria e.g. all those people who own a car.
- Preprocessing: this is the data cleansing stage where certain information is removed which is unnecessary. Eg: remove the gender of patient when studying pregnancy.
- Transformation: In this process, data is transformed into a form suitable for the data mining process. Data is consolidated so that the mining process is more efficient and the patterns are easier to understand.
- Data Mining: Data Mining is a process to identify interesting patterns and knowledge from a large amount of data. In these steps, intelligent patterns are applied to extract the data patterns. The data is represented in the form of patterns such as language L, facts F, statement S etc. and models are structured using classification and clustering techniques.
- Interpretation: The patterns identified by the system are interpreted into knowledge which can then be used to support human decision-making.
There are four main objective of data mining as:
- Sequence or path analysis: Finding patterns where one event leads to another, later event.
- Classification: Finding whether certain facts fall into predefined groups.
- Clustering: Finding groups of related facts not previously known.
- Forecasting: Discovering patterns in data that can lead to reasonable predictions.
Use of Data Mining:
Data mining is widely used in diverse areas. There are numbers of commercial data mining system available today and yet there are many challenges in this field. The various applications and the trend of data mining are describing below.
Data Mining Applications
Here is the list of areas where data mining is widely used
- Financial Data Analysis
- Retail Industry
- Telecommunication Industry
- Biological Data Analysis
- Intrusion Detection
- Other Scientific Applications
Financial Data Analysis
The financial data in banking and financial industry is generally reliable and of high quality which facilitates systematic data analysis and data mining. Some of the typical cases are as follows:
- Design and construction of data warehouses for multidimensional data analysis and data mining.
- Loan payment prediction and customer credit policy analysis.
- Classification and clustering of customers for targeted marketing.
- Detection of money laundering and other financial crimes.
Retail Industry
Data Mining has its great application in Retail Industry because it collects large amount of data from on sales, customer purchasing history, goods transportation, consumption and services. It is natural that the quantity of data collected will continue to expand rapidly because of the increasing ease, availability and popularity of the web.
Data mining in retail industry helps in identifying customer buying patterns and trends that lead to improved quality of customer service and good customer retention and satisfaction. Here is the list of examples of data mining in the retail industry −
- Design and Construction of data warehouses based on the benefits of data mining.
- Multidimensional analysis of sales, customers, products, time and region.
- Analysis of effectiveness of sales campaigns.
- Customer Retention.
- Product recommendation and cross-referencing of items.
Telecommunication Industry
Today the telecommunication industry is one of the most emerging industries providing various services such as fax, pager, cellular phone, internet messenger, images, e-mail, web data transmission, etc. Due to the development of new computer and communication technologies, the telecommunication industry is rapidly expanding. This is the reason why data mining is become very important to help and understand the business.
Data mining in telecommunication industry helps in identifying the telecommunication patterns, catch fraudulent activities, make better use of resource, and improve quality of service.
Here is the list of examples for which data mining improves telecommunication services −
- Multidimensional Analysis of Telecommunication data.
- Fraudulent pattern analysis.
- Identification of unusual patterns.
- Multidimensional association and sequential patterns analysis.
- Mobile Telecommunication services.
- Use of visualization tools in telecommunication data analysis.
Biological Data Analysis
In recent times, we have seen a tremendous growth in the field of biology such as genomics, proteomics, functional Genomics and biomedical research. Biological data mining is a very important part of Bioinformatics.
Following are the aspects in which data mining contributes for biological data analysis −
- Semantic integration of heterogeneous, distributed genomic and proteomic databases.
- Alignment, indexing, similarity search and comparative analysis multiple nucleotide sequences.
- Discovery of structural patterns and analysis of genetic networks and protein pathways.
- Association and path analysis.
- Visualization tools in genetic data analysis.
Other Scientific Applications
The applications discussed above tend to handle relatively small and homogeneous data sets for which the statistical techniques are appropriate. Huge amount of data have been collected from scientific domains such as geosciences, astronomy, etc. A large amount of data sets is being generated because of the fast numerical simulations in various fields such as climate and ecosystem modeling, chemical engineering, fluid dynamics, etc.
Following are the applications of data mining in the field of Scientific Applications −
- Data Warehouses and data preprocessing.
- Graph-based mining.
- Visualization and domain specific knowledge.
Intrusion Detection
Intrusion refers to any kind of action that threatens integrity, confidentiality, or the availability of network resources. In this world of connectivity, security has become the major issue. With increased usage of internet and availability of the tools and tricks for intruding and attacking network prompted intrusion detection to become a critical component of network administration.
Here is the list of areas in which data mining technology may be applied for intrusion detection −
- Development of data mining algorithm for intrusion detection.
- Association and correlation analysis, aggregation to help select and build discriminating attributes.
- Analysis of Stream data.
- Distributed data mining.
- Visualization and query tools.
Data Warehouse:
Introduction to Data Warehouse:
A data warehouse (DW) is a collection of corporate information and data derived from operational systems and external data sources. A data warehouse is designed to support business decisions by allowing data consolidation, analysis and reporting at different aggregate levels. Data is populated into the DW through the processes of extraction, transformation and loading.
In a data warehouse, data from many heterogeneous sources is extracted into a single area, transformed according to the decision support system needs and stored into the warehouse. For example: company stores information pertaining to its employees, their salaries, developed products, customer information, sales and invoices. The CEO might want to ask a question pertaining to the latest cost-reduction measures; the answers will involve analysis of all of this data. This is a main service of the data warehouse, i.e., allowing executives to reach business decisions based on all these disparate raw data items.
Thus, a data warehouse contributes to future decision making. As in the above example, a firm administrator can query warehouse data to find out the market demand of a particular product, sales data by geographical region or answers other inquiries. This provides insight about required steps to more effectively market a particular product. Unlike an operational data store, a data warehouse contains aggregate historical data, which may be analyzed to reach critical business decisions. Despite associated costs and effort, most major corporations today use data warehouses.

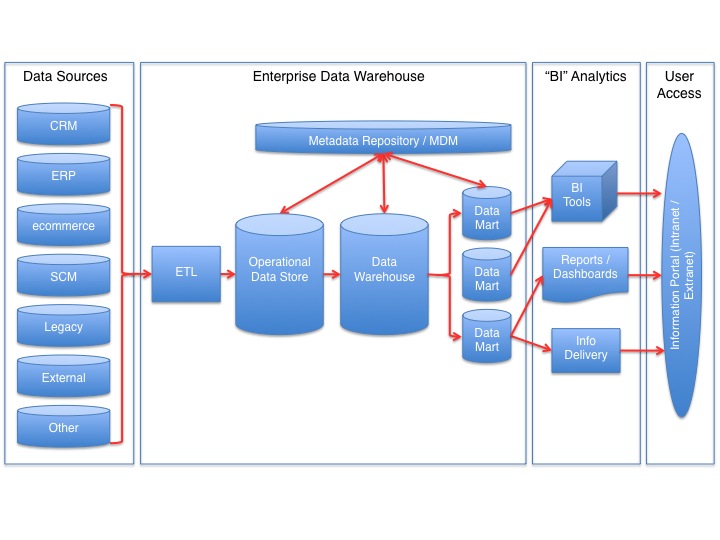
Fig: Data warehouse
It provides the multidimensional view of consolidated data in a warehouse. Additionally, the data warehouse environment supports ETL (Extraction, Transform and Load) solutions, data mining capabilities, statistical analysis, reporting and OLAP (Online Analytical Processing) Tools, which help in interactive and efficient data analysis in a multifaceted view.
The major characteristics of data warehouse are:
Subject Oriented: it deals with subject area of organization. Example: an insurance company uses a data warehouse organize their data by customer, premium, and claim etc.
Integrated: data warehouse receives data from different resources. Filtering and transforming data from different resources into one consistent database is known as integration.
Non-Volatile: data are updated frequently. Data warehouse can save data for long run.
Time-variant: data can store for long time so, later older data can user for forecasting.
There are three main components of data warehousing:
- A data integration layer that extracts data from operational systems, such as Excel, ERP, CRM or financial applications.
- A data staging area where data is cleanup and organized.
- A presentation area where data is warehoused and made available for use.
Use of Data Warehouse:
Data Warehouse are used for
- Carrying out data mining to gain new insights from the information held in many large databases
- Conducting market research by analyzing large volumes of data in-depth
- An online business analyzing user behavior to make business decisions
Application areas of data warehouse are:
Here, are most common sectors where Data warehouse is used:
Airline:
In the Airline system, it is used for operation purpose like crew assignment, analyses of route profitability, frequent flyer program promotions, etc.
Banking:
It is widely used in the banking sector to manage the resources available on desk effectively. Few banks also used for the market research, performance analysis of the product and operations.
Healthcare:
Healthcare sector also used Data warehouse to strategize and predict outcomes, generate patient's treatment reports, share data with tie-in insurance companies, medical aid services, etc.
Public sector:
In the public sector, data warehouse is used for intelligence gathering. It helps government agencies to maintain and analyze tax records, health policy records, for every individual.
Investment and Insurance sector:
In this sector, the warehouses are primarily used to analyze data patterns, customer trends, and to track market movements.
Retain chain:
In retail chains, Data warehouse is widely used for distribution and marketing. It also helps to track items, customer buying pattern, promotions and also used for determining pricing policy.
Telecommunication:
A data warehouse is used in this sector for product promotions, sales decisions and to make distribution decisions.
Hospitality Industry:
This Industry utilizes warehouse services to design as well as estimate their advertising and promotion campaigns where they want to target clients based on their feedback and travel patterns.





